
转:http://blog.csdn.net/tianlesoftware/article/details/5826546
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式。 之前打算在sqlplus中用执行计划的,但是格式看起来有点乱,就用Toad做了3个截图。

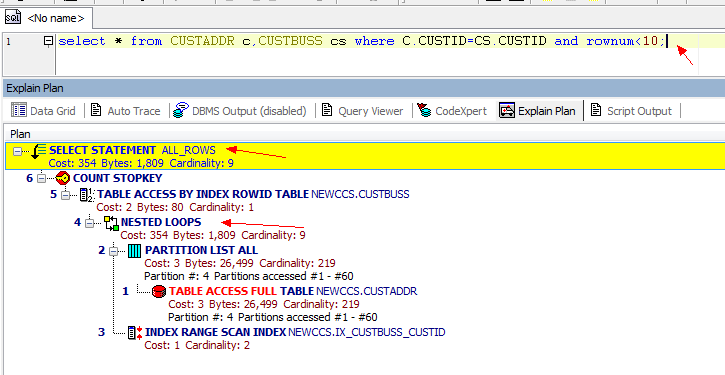
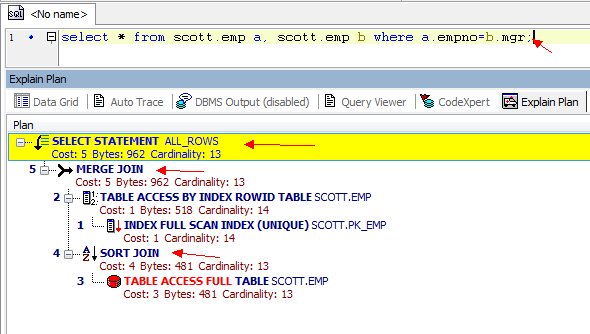
从3张图里我们看到了几点信息:
1. CBO 使用的ALL_ROWS模式
Oracle Optimizer CBO RBO
http://blog.csdn.net/tianlesoftware/archive/2010/08/19/5824886.aspx
2. 表之间的连接用了hash Join, Nested loops,Sort Merge Join
多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join. 下面来介绍三种不同连接的不同:
一. NESTED LOOP:
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表(CBO 默认外表是驱动表),而且在内表的连接字段上一定要有索引。当然也可以用ORDERED 提示来改变CBO默认的驱动表,使用USE_NL(table_name1 table_name2)可是强制CBO 执行嵌套循环连接。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候.
步骤:确定一个驱动表(outer table),另一个表为inner table,驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且inner表需要有有效的访问方法(Index)。需要注意的是:JOIN的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间是最快的。
cost = outer access cost + (inner access cost * outer cardinality)
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
| 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
| 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
EMPLOYEES为outer table, JOBS为inner table.
二. HASH JOIN :
散列连接是CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
也可以用USE_HASH(table_name1 table_name2)提示来强制使用散列连接。如果使用散列连接HASH_AREA_SIZE 初始化参数必须足够的大,如果是9i,Oracle建议使用SQL工作区自动管理,设置WORKAREA_SIZE_POLICY 为AUTO,然后调整PGA_AGGREGATE_TARGET 即可。
Hash join在两个表的数据量差别很大的时候.
步骤:将两个表中较小的一个在内存中构造一个HASH表(对JOIN KEY),扫描另一个表,同样对JOIN KEY进行HASH后探测是否可以JOIN。适用于记录集比较大的情况。需要注意的是:如果HASH表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘的temporary segment,则会多一个写的代价,会降低效率。
cost = (outer access cost * # of hash partitions) + inner access cost
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 665 | 13300 | 8 (25)|
| 1 | HASH JOIN | | 665 | 13300 | 8 (25)|
| 2 | TABLE ACCESS FULL | ORDERS | 105 | 840 | 4 (25)|
| 3 | TABLE ACCESS FULL | ORDER_ITEMS | 665 | 7980 | 4 (25)|
--------------------------------------------------------------------------
ORDERS为HASH TABLE,ORDER_ITEMS扫描
三.SORT MERGE JOIN
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。可以使用USE_MERGE(table_name1 table_name2)来强制使用排序合并连接.
Sort Merge join 用在没有索引,并且数据已经排序的情况.
cost = (outer access cost * # of hash partitions) + inner access cost
步骤:将两个表排序,然后将两个表合并。通常情况下,只有在以下情况发生时,才会使用此种JOIN方式:
1.RBO模式
2.不等价关联(>,<,>=,<=,<>)
3.HASH_JOIN_ENABLED=false
4.数据源已排序
四. 三种连接工作方式比较:
Hash join的工作方式是将一个表(通常是小一点的那个表)做hash运算,将列数据存储到hash列表中,从另一个表中抽取记录,做hash运算,到hash 列表中找到相应的值,做匹配。
Nested loops 工作方式是从一张表中读取数据,访问另一张表(通常是索引)来做匹配,nested loops适用的场合是当一个关联表比较小的时候,效率会更高。
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配,因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能。
***********************************************
转:http://blog.csdn.net/java3344520/article/details/5507327
SQL调优 之 连接方式
Join是一种试图将两个表结合在一起的谓词,一次只能连接2个表,表连接也可以被称为表关联。在后面的叙述中,使用”row source”来代替”表”,因为使用row source更严谨一些,并且将参与连接的2个row source分别称为row source1和row source 2。Join过程的各个步骤经常是串行操作,即使相关的row source可以被并行访问,即可以并行的读取做join连接的两个row source的数据,但是在将表中符合限制条件的数据读入到内存形成row source后,join的其它步骤一般是串行的。有多种方法可以将2个表连接起来,当然每种方法都有自己的优缺点,每种连接类型只有在特定的条件下才会发挥出其最大优势。
row source(表)之间的连接顺序对于查询的效率有非常大的影响。通过首先存取特定的表,即将该表作为驱动表,这样可以先应用某些限制条件,从而得到一个较小的row source,使连接的效率较高,这也就是我们常说的要先执行限制条件的原因。一般是在将表读入内存时,应用where子句中对该表的限制条件。
根据2个row source的连接条件的中操作符的不同,可以将连接分为等值连接(如WHERE A.COL3 = B.COL4)、非等值连接(WHERE A.COL3 > B.COL4)、外连接(WHERE A.COL3 = B.COL4(+))。上面的各个连接的连接原理都基本一样,所以为了简单期间,下面以等值连接为例进行介绍。
无论连接操作符如何,典型的连接类型共有3种:
排序 - - 合并连接(Sort Merge Join (SMJ) )
嵌套循环(Nested Loops (NL) )
哈希连接(Hash Join)
排序 - - 合并连接(Sort Merge Join, SMJ)
内部连接过程:
1) 首先生成row source1需要的数据,然后对这些数据按照连接操作关联列(如A.col3)进行排序。
2) 随后生成row source2需要的数据,然后对这些数据按照与sort source1对应的连接操作关联列
(如B.col4)进行排序。
3) 最后两边已排序的行被放在一起执行合并操作,即将2个row source按照连接条件连接起来
下面是连接步骤的图形表示:
MERGE
/ /
SORT SORT
| |
Row Source 1 Row Source 2
row source已经在连接关联列上被排序,则该连接操作就不需要再进行sort操作,这样可以大大提高这种连接操作的连接速度,因为排序是个极其费资源的操作,特别是对于较大的表。 预先排序的row source包括已经被索引的列(如a.col3或b.col4上有索引)或row source已经在前面的步骤中被排序了。
尽管合并两个rowsource的过程是串行的,但是可以并行访问这两个rowsource(如并行读入数据和排序).
SMJ连接的例子:(以下是在网络的的例子,在ORACLE 9I里的执行计划已经改变)
SQL> explain plan for
select /*+ordered */ e.deptno, d.deptno from emp e, dept d
where e.deptno = d.deptno order by e.deptno, d.deptno;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=14 Bytes=84)
1 0 SORT (ORDER BY) (Cost=4 Card=14 Bytes=84)
2 1 NESTED LOOPS (Cost=3 Card=14 Bytes=84)
3 2 TABLE ACCESS (FULL) OF 'EMP' (TABLE) (Cost=3 Card=14 Bytes=42)
4 2 INDEX (UNIQUE SCAN) OF 'PK_DEPT' (INDEX (UNIQUE)) (Cost=0 Card=1 Bytes=3)
Sort merge join性能开销几乎都在前两步。一般是在没有索引的情况下,9i开始已经很少出现了,因为其排序成本高,大多为hash join替代了。 通常情况下hash join的效果都比sort merge join要好,然而如果行源已经被排过序,在执行sort merge join时不需要再排序了,这时sort merge join的性能会优于hash join。在全表扫描比索引范围扫描再通过rowid进行表访问更可取的情况下,sort merge join会比nested loops性能更佳。
嵌套循环(Nested Loops, NL)
这个连接方法有驱动表(外部表)的概念。其实,该连接过程就是一个2层嵌套循环,所以外层循环的次数越少越好,这也就是我们为什么将小表或返回较小row source的表作为驱动表(用于外层循环)的理论依据。但是这个理论只是一般指导原则,因为遵循这个理论并不能总保证使语句产生i/O次数最少。有时 不遵守这个理论依据,反而会获得更好的效率。如果使用这种方法,决定使用哪个表作为驱动表很重要。有时如果驱动表选择不正确,将会导致语句的性能很差、很差。
如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。NESTED LOOPS有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
如果不使用并行操作,最好的驱动表是那些应用了where 限制条件后,可以返回较少行数据的的表,所以大表也可能称为驱动表,关键看限制条件。对于并行查询,我们经常选择大表作为驱动表,因为大表可以充分利用并行功能。当然,有时对查询使用并行操作并不一定会比查询不使用并行操作效率高,因为最后可能每个表只有很少的行符合限制条件,而且还要看你的硬件配置是否 可以支持并行(如是否有多个CPU,多个硬盘控制器),所以要具体问题具体对待。
哈希连接(Hash Join, HJ) (看到有关HJ的专题文章,下次转载)
较小的row source被用来构建hash table与bitmap,第2个row source被用来被hansed,并与第一个row source生成的hash table进行匹配,以便进行进一步的连接。Bitmap被用来作为一种比较快的查找方法,来检查在hash table中是否有匹配的行。特别的,当hash table比较大而不能全部容纳在内存中时,这种查找方法更有用。这种连接方法也有NL连接中所谓的驱动表的概念,被构建为hash table与bitmap的表为驱动表,当被构建的hash table与bitmap能被容纳在内存中时,这种连接方式的效率极高。
***********************************************
转:http://blog.csdn.net/java3344520/article/details/5509743
Oracle中的Hash Join祥解
一、 hash join概念
Hashjoin(HJ)是一种用于equi-join(而anti-join就是使用NOT IN时的join)的技术。
在Oracle中,它是从7.3开始引入的,以代替sort-merge和nested-loop join方式,
提高效率。在CBO(hash join只有在CBO才可能被使用到)模式下,优化器计算代价时,
首先会考 虑hash join。可以通过提示use_hash来强制使用hash join,
也可以通过修改会话或数据库参数HASH_JOIN_ENABLED=FALSE(默认为TRUE)强制不使用hash join。
Hash join的主要资源消耗在于CPU(在内存中创建临时的hash表,并进行hash计算),而merge join的资源消耗主要在于此盘IO(扫描表或索引)。在并行系统中,
hash join对CPU的消耗更加明显。所以在CPU紧张时,最好限制使用hash join。
在绝大多数情况下,hash join效率比其他join方式效率更高:
在Sort-Merge Join(SMJ),两张表的数据都需要先做排序,然后做merge。因此效率相对最差;
Nested-Loop Join(NL)效率比SMJ更高。特别是当驱动表的数据量很大(集的势高)时。这样可以并行扫描内表。
Hash join效率最高,因为只要对两张表扫描一次。Hash join一般用于一张小表和一张大表进行join时。Hash join的过程大致如下(下面所说的内存就指sort area,关于过程,后面会作详细讨论):
1. 一张小表被hash在内存中。因为数据量小,所以这张小表的大多数数据已经驻入在内存中,剩下的少量数据被放置在临时表空间中;
2. 每读取大表的一条记录,就和小表中内存中的数据进行比较,如果符合,则立即输出数据(也就是说没有读取临时表空间中的小表的数
据)。而如果大表的数据与小表中临时表空间的数据相符合,则不直接输出,而是也被存储临时表空间中。
3. 当大表的所有数据都读取完毕,将临时表空间中的数据以其输出。
如果小表的数据量足够小(小于hash area size),那所有数据就都在内存中了,可以避免对临时表空间的读写。
如果是并行环境下,前面中的第2步就变成如下了:
2. 每读取一条大表的记录,和内存中小表的数据比较,如果符合先做join,而不直接输出,直到整张大表数据读取完毕。如果内存足够,
Join好的数据就保存在内存中。否则,就保存在临时表空间中。
二、 Oracle中与hash join相关的参数
首先,要注意的是,hash join只有在CBO方式下才会被激活。在oracle中与hash join相关的参数主要有以下几个:
1. HASH_JOIN_ENABLED
这个参数是控制查询计划是否采用hash join的“总开关”。它可以在会话级和实例级被修改。默认为TRUE,既可以(不是一定,要看优化器计算出来的代价)使用。如果设为FALSE,则禁止使用hash join。
2. HASH_AREA_SIZE
这个参数控制每个会话的hash内存空间有多大。它也可以在会话级和实例级被修改。默认(也是推荐)值是sort area空间大小的两倍(2*SORT_AREA_SIZE)。要提高hash join的效率,就一定尽量保证sort area足够大,能容纳下整个小表的数据。但是因为每个会话都会开辟一个这么大的内存空间作为hash内存,所以不能过大(一般不建议超过2M)。
在Oracle9i及以后版本中,Oracle不推荐在dedicated server中使用这个参数来设置hash内存,而是推荐通过设置
PGA_AGGRATE_TARGET参数来自动管理PGA内存。保留HASH_AREA_SIZE只是为了向后兼容。在dedicated server中,hash area是从PGA中分配的,而在MTS(Multi-Threaded Server)中,hash area是从UGA中分配的。另外,还要注意的是,每个会话并不一定只打开一个hash area,因为一个查询中可能不止一个hash join,这是就会相应同时打开多个hash area。
3. HAHS_MULTIBLOCK_IO_COUNT
这个参数决定每次读入hash area的数据块数量。因此它会对IO性能产生影响。他只能在init.ora或spfile中修改。在8.0及之前版本,它的默认值是1,在8i及以后版本,默认值是0。一般设置为1-(65536/DB_BLOCK_SIZE)。在9i中,这个参数是一个隐藏参数:_HASH_MULTIBLOCK_IO_COUNT,可以通过表x$ksppi查询和修改。另外,在MTS中,这个参数将不起作用(只会使用1)。它的最大值受到OS的IO带宽和DB_BLOCK_SIZE的影响。既不能大于MAX_IO_SIZE/DB_BLOCK_SIZE。
在8i及以后版本,如果这个值设置为0,则表示在每次查询时,Oracle自己自动计算这个值。这个值对IO性能影响非常大,因此,建议不要修改这个参数,使用默认值0,让Oracle自己去计算这个值。
如果一定要设置这个值,要保证以下不等式能成立:
R/M < Po2(M/C)
其中,R表示小表的大小;M=HASH_AREA_SIZE*0.9;Po2(n)为n的2次方;C=HASH_MULTIBLOCK_IO_COUNT*DB_BLOCK_SIZE。
三、 Hash join的过程
一次完整的hash join如下:
1.计算小表的分区(bucket)数决定hash join的一个重要因素是小表的分区(bucket)数。这个数字由hash_area_size、hash_multiblock_io_count和db_block_size参数共同决定。Oracle会保留hash area的20%来存储分区的头信息、hash位图信息和hash表。因此,这个数字的计算公式是:
Bucket数=0.8*hash_area_size/(hash_multiblock_io_count*db_block_size)
2. Hash计算
读取小表数据(简称为R),并对每一条数据根据hash算法进行计算。Oracle采用两种hash算法进行计算,计算出能达到最快速度的hash值(第一hash值和第二hash值)。而关于这些分区的全部hash值(第一hash值)就成为hash表。
3.存放数据到hash内存中
将经过hash算法计算的数据,根据各个bucket的hash值(第一hash值)分别放入相应的bucket中。第二hash值就存放在各条记录中。
4.创建hash位图
与此同时,也创建了一个关于这两个hash值映射关系的hash位图。
5.超出内存大小部分被移到磁盘
如果hash area被占满,那最大一个分区就会被写到磁盘(临时表空间)上去。任何需要写入到磁盘分区上的记录都会导致磁盘分区被更新。这样的话,就会严重影响性能,因此一定要尽量避免这种情况。
2-5一直持续到整个表的数据读取完毕。
6.对分区排序
为了能充分利用内存,尽量存储更多的分区,Oracle会按照各个分区的大小将他们在内存中排序。
7.读取大表数据,进行hash匹配
接下来就开始读取大表(简称S)中的数据。按顺序每读取一条记录,计算它的hash值,并检查是否与内存中的分区的hash值一致。如果是,返回join数据。如果内存中的分区没有符合的,就将S中的数据写入到一个新的分区中,这个分区也采用与计算R一样的算法计算出hash值。也就是说这些S中的数据产生的新的分区数应该和R的分区集的分区数一样。这些新的分区被存储在磁盘(临时表空间)上。
8.全大表全部数据的读取
一直按照7进行,直到大表中的所有数据的读取完毕。
9.处理没有join的数据
这个时候就产生了一大堆join好的数据和从R和S中计算存储在磁盘上的分区。
10.二次hash计算
从R和S的分区集中抽取出最小的一个分区,使用第二种hash函数计算出并在内存中创建hash表。采用第二种hash函数的原因是为了使数据分布性更好。
11.二次hash匹配
在从另一个数据源(与hash在内存的那个分区所属数据源不同的)中读取分区数据,与内存中的新hash表进行匹配。返回join数据。
12.完成全部hash join
继续按照9-11处理剩余分区,直到全部处理完毕。整个hash join就完成了。
四、关于唯一健值的hash位图
这个位图包含了每个hash分区是否有有值的信息。它记录了有数据的分区的hash值。这个位图的最大作用就是,如果S表中的数据没有与内存中的hash表匹配上,先查看这个位图,已决定是否将没有匹配的数据写入磁盘。那些不可能匹配到的数据(即位图上对应的分区没有数据)就不再写入磁盘。
以上转自:http://www.hellodba.com/Doc/Oracle_Hash_Join.htm



相关推荐
Oracle的三种表连接方式 详细讲述• sort merge join(SMJ) • nest loop(NL) • hash join(HJ)
数据库中JOIN操作的实现主要有三种:嵌套循环连接(Nested Loop Join),归并连接(Merge Join)和散列连接或者哈稀连接(Hash Join)。其中嵌套循环连接又视情况又有两种变形:块嵌套循环连接和索引嵌套循环连接。
Hash分区是Oracle实现表分区的三种基本分区方式之一。对于那些无法有效划分分区范围的大表,或者出于某些特殊考虑的设计,需要使用Hash分区,下面介绍使用方法
Sql中的三种物理连接操作 嵌套循环连接(Nested Loop Join) 合并连接(Merge Join) 哈希匹配(Hash Join)
针对这种情况,Oracle在连接键利用一个hash函数将build input和probe input分割成多个不相连的分区(分别记作Si和Bi),这个阶段叫做分区阶段;然后各自相应的分区,即Si和Bi再做Hash join,这个阶段叫做join阶段。
hash join 原理和算法 1.Hash Join概述 2.Hash Join原理 3.Hash Join算法 4.Hash Join的成本
Hash join算法原理 详细讲述了oracle sql语句的连接方式 对于sql调优提高有很大帮助
其中最引人注目的莫过于多表连接查询支持 hash join 方式了。我们先来看看官方的描述: MySQL 实现了用于内连接查询的 hash join 方式。例如,从 MySQL 8.0.18 开始以下查询可以使用 hash join 进行连接查询: ...
oracle hash join算法原理
数据库 我自己在 Java 中实现了 SortMergeJoin 和 HashJoin(来自 SQL 的著名 INNER JOIN)。 在更多信息。
Oracle中hash join研究.pdf
Oracle CBO 学习笔记之(1) : 深入理解Oracle Hash Join的代价模型及其执行流程:word,pdf,图例
NULL 博文链接:https://juji1010.iteye.com/blog/1535638
ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。 ...
1:列举几种表连接方式 hash join/merge join/nest loop(cluster join)/index join 2:不借助第三方工具,怎样查看sql的执行计划 set autot on explain plan set statement_id = &item_id for &sql; ...
Join,HashJoin这三种物理连接中的一种。理解这三种物理连接是理解在表连接时解决性能问题的基础,下面我来对这三种连接的原理,适用场景进行描述。循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,...
在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join这三种物理连接中的一种。理解这三种物理...
1:列举几种表连接方式 hash join/merge join/nest loop(cluster join)/index join 2:不借助第三方工具,怎样查看sql的执行计划 set autot on explain plan set statement_id = &item_id for &sql; ...